Converse com LLMs Locais Gratuitos no Zotero
Introdução
Atualmente, os modelos de linguagem de grande escala (LLMs) de código aberto estão se desenvolvendo rapidamente. Embora não sejam tão bons quanto os LLMs comerciais pagos, alguns LLMs de código aberto são suficientes até certo ponto em cenários de resumo automático, redação de revisões de artigos e outras leituras auxiliares de artigos. E eles são completamente gratuitos para sempre. Tudo o que você precisa é do seu computador pessoal e de uma fonte de alimentação suficiente. Agora, o PapersGPT oferece suporte à execução contínua de LLMs locais no Zotero, seja na plataforma Windows ou Mac, pode ser executado facilmente.
Execução de LLMs gratuitos com um clique no Zotero
Inicializar ambiente
Quando você instala e inicia o PapersGPT (pelo menos v0.2.0) pela primeira vez, o sistema levará algum tempo para inicializar automaticamente as bibliotecas dependentes e os pacotes de instalação necessários para executar LLMs locais. Certifique-se de que a rede esteja boa e possa se conectar ao GitHub e ao HuggingFace. Este processo é executado automaticamente em segundo plano e os usuários não precisam se preocupar com nenhuma configuração e instalação manual tediosa do ambiente. Em alguns ambientes de sistema no Windows, o firewall pode alertar que há riscos. Conceda as permissões relevantes para garantir o bom andamento do processo de instalação.
Escolha o modelo que você gosta
Quando o ambiente de execução dos LLMs for inicializado, a opção LLM Local aparecerá no PapersGPT e será configurada de acordo com o ambiente da máquina local, com LLMs de código aberto integrados de tamanhos compatíveis. Os modelos locais gratuitos suportados são mostrados na tabela a seguir.
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
Observe que, devido à limitação da memória da GPU no seu PC ou laptop, nem todos os modelos serão exibidos. Apenas os modelos cujo tamanho é menor que a memória da sua GPU poderão ser exibidos. Uma vez que os LLMs são exibidos para escolha, eles podem ser executados com segurança na GPU da sua máquina local e terão prioridade para execução na maior placa GPU local.
Download dos modelos
Após selecionar um modelo específico, como gemma 3 4b, o modelo será baixado automaticamente do HuggingFace para o computador local. Como os LLMs geralmente são grandes, eles costumam levar algum tempo para baixar. O progresso do download é exibido no PapersGPT. Após o download do modelo, o sistema em segundo plano carregará e iniciará automaticamente o serviço de inferência do LLM local.
Conversar com LLMs locais
Converse com LLMs locais ao ler artigos. Você pode ler um único artigo ou vários artigos juntos. Por exemplo, você pode gerar uma revisão de literatura com base em vários artigos relacionados no Zotero. É muito conveniente e fácil de usar.
Notas Importantes
O agente do PapersGPT pode ser erroneamente definido como Trojan ou vírus no Windows. Os agentes relacionados do PapersGPT podem ser erroneamente definidos como Trojan ou vírus pelo Microsoft Defender ou outro software antivírus. Neste caso, você pode observar alguns fenômenos anormais:
O item "LLM Local" no lado esquerdo do PapersGPT não aparece. Os modelos locais não podem ser baixados para o seu computador. Os modelos locais não podem fornecer serviço de chat para você.
Portanto, se você quiser usar os LLMs Locais no seu Windows, permita que os agentes seguros do PapersGPT sejam executados no seu dispositivo no Microsoft Defender ou software antivírus.
Não converse com LLMs locais no modo de economia de energia
Ao conversar com PDFs usando LLMs locais, certifique-se de que seu computador não esteja funcionando em modo de baixo consumo de energia, modo de economia de energia ou modos similares. Isso porque conversar com PDFs usando LLMs locais requer muitos cálculos da GPU, e modos como economia de energia afetarão o desempenho da computação e tornarão a resposta do PapersGPT lenta.
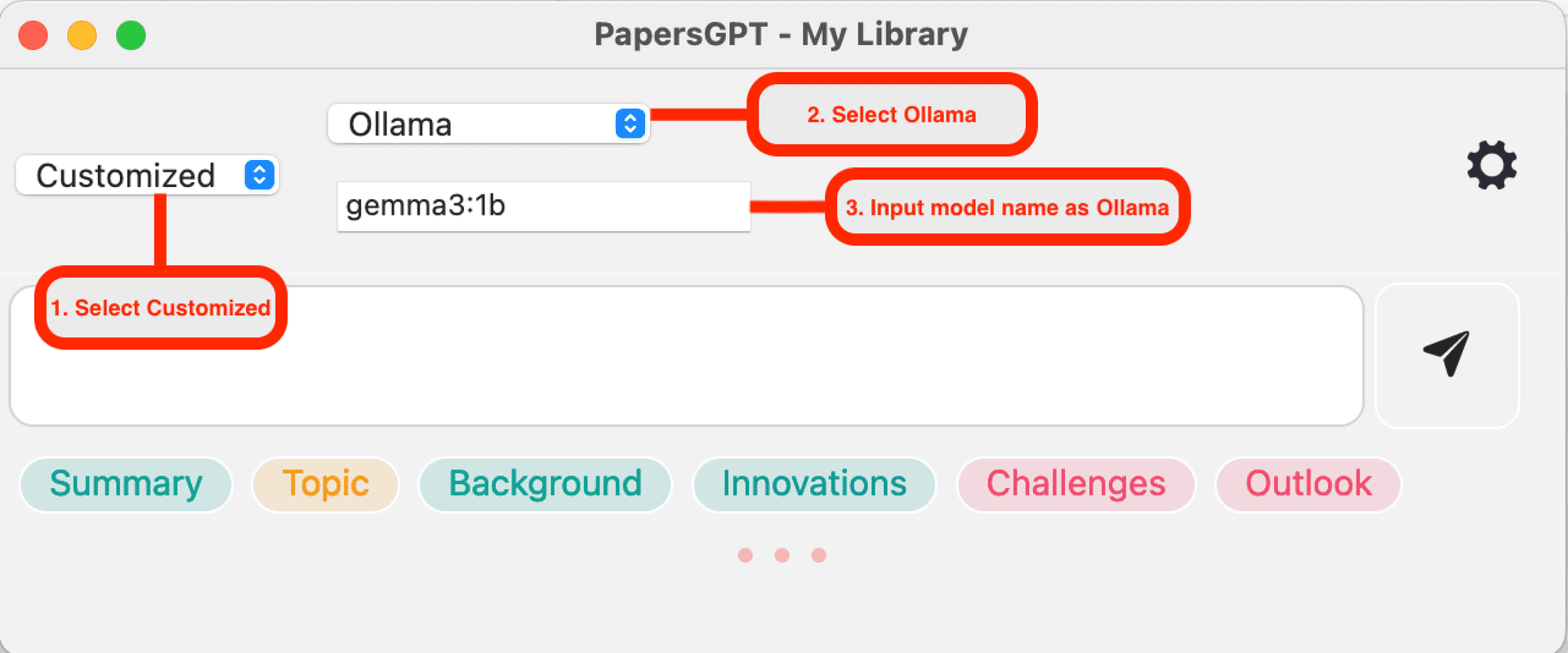
Compatível com Ollama
Se você está acostumado a usar o aplicativo Ollama para iniciar o serviço LLM local, basta inserir o nome do modelo que é o mesmo do Ollama no PapersGPT, como 'gemma3:1b'