Czatuj z darmowymi lokalnymi modelami LLM w Zotero
Wprowadzenie
Obecnie otwartoźródłowe duże modele językowe (LLM) rozwijają się bardzo szybko. Chociaż nie są one tak dobre jak płatne komercyjne modele LLM, niektóre modele open source są w pewnym stopniu wystarczające w scenariuszach automatycznego podsumowywania, pisania recenzji artykułów i innego pomocniczego czytania prac. I są one całkowicie darmowe na zawsze. Wszystko, czego potrzebujesz, to Twój osobisty komputer i wystarczające zasilanie. PapersGPT obsługuje teraz płynne uruchamianie lokalnych modeli LLM w Zotero, zarówno na platformie Windows, jak i Mac.
Uruchamianie darmowych modeli LLM w Zotero jednym kliknięciem
Inicjalizacja środowiska
Przy pierwszej instalacji i uruchomieniu PapersGPT (co najmniej v0.2.0) system potrzebuje trochę czasu, aby automatycznie zainicjalizować biblioteki zależne i pakiety instalacyjne wymagane do uruchamiania lokalnych modeli LLM. Upewnij się, że sieć działa prawidłowo i może łączyć się z GitHub i HuggingFace. Ten proces działa automatycznie w tle, a użytkownicy nie muszą się martwić o żadną żmudną ręczną konfigurację środowiska i instalację. W niektórych środowiskach systemowych na Windows zapora sieciowa może ostrzegać o ryzyku. Przyznaj odpowiednie uprawnienia, aby zapewnić płynny przebieg procesu instalacji.
Wybierz model, który Ci się podoba
Gdy środowisko do uruchamiania LLM zostanie zainicjalizowane, opcja Local LLM pojawi się w PapersGPT i zostanie skonfigurowana zgodnie ze środowiskiem lokalnej maszyny, z wbudowanymi modelami open source LLM o dopasowanych rozmiarach. Obsługiwane lokalne darmowe modele są przedstawione w poniższej tabeli.
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
Należy pamiętać, że ze względu na ograniczenia pamięci GPU na komputerze lub laptopie nie wszystkie modele będą wyświetlane. Wyświetlane będą tylko modele, których rozmiar jest mniejszy niż dostępna pamięć GPU. Gdy modele LLM są wyświetlane do wyboru, mogą być bezpiecznie uruchamiane na GPU lokalnej maszyny i będą priorytetowo uruchamiane na największej lokalnej karcie GPU.
Pobieranie modeli
Po wybraniu konkretnego modelu, na przykład gemma 3 4b, model zostanie automatycznie pobrany z HuggingFace na lokalny komputer. Ponieważ modele LLM są zazwyczaj duże, ich pobranie zajmuje zwykle trochę czasu. Postęp pobierania jest wyświetlany w PapersGPT. Po pobraniu modelu system automatycznie załaduje i uruchomi lokalną usługę wnioskowania LLM w tle.
Czatuj z lokalnymi modelami LLM
Czatuj z lokalnymi modelami LLM podczas czytania prac. Możesz czytać pojedynczy artykuł lub wiele artykułów jednocześnie. Na przykład możesz wygenerować przegląd literatury na podstawie wielu powiązanych artykułów w Zotero. Jest to bardzo wygodne i łatwe w użyciu.
Ważne uwagi
Agent PapersGPT może być błędnie rozpoznawany jako trojan lub wirus na Windows. Powiązane programy PapersGPT mogą być błędnie klasyfikowane jako trojan lub wirus przez Microsoft Defender lub inne oprogramowanie antywirusowe. W takim przypadku mogą wystąpić nieprawidłowości:
Opcja „Local LLM” po lewej stronie PapersGPT nie pojawia się. Lokalne modele nie mogą być pobrane na komputer. Lokalne modele nie mogą świadczyć usługi czatu.
Jeśli chcesz korzystać z lokalnych modeli LLM na Windows, zezwól bezpiecznym agentom PapersGPT na działanie na Twoim urządzeniu w Microsoft Defender lub oprogramowaniu antywirusowym.
Nie czatuj z lokalnymi modelami LLM w trybie oszczędzania energii
Podczas czatowania z plikami PDF przy użyciu lokalnych modeli LLM upewnij się, że komputer nie pracuje w trybie niskiego zużycia energii, trybie oszczędzania energii ani w podobnych trybach. Dzieje się tak dlatego, że czatowanie z plikami PDF przy użyciu lokalnych LLM wymaga dużej mocy obliczeniowej GPU, a tryby oszczędzania energii wpłyną na wydajność obliczeń i sprawią, że PapersGPT będzie odpowiadać wolniej.
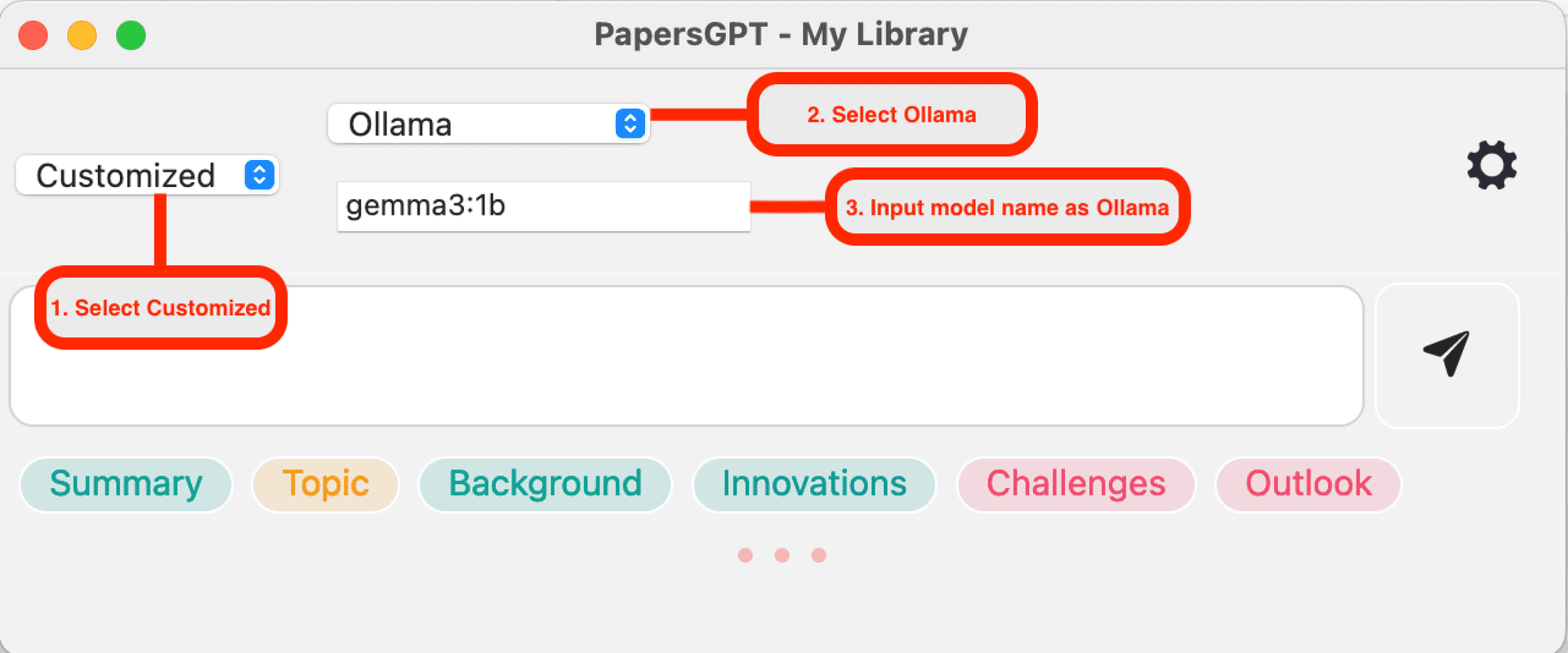
Kompatybilność z Ollama
Jeśli jesteś przyzwyczajony do korzystania z aplikacji Ollama do uruchamiania lokalnej usługi LLM, możesz po prostu wpisać nazwę modelu taką samą jak w Ollama w PapersGPT, na przykład „gemma3:1b”.