Zoteroでローカル無料LLMとチャット
はじめに
現在、オープンソースの大規模言語モデル(LLM)は急速に発展しています。有料の商用LLMには及ばないものの、一部のオープンソースLLMは自動要約、論文レビューの作成、その他の論文読解補助のシナリオである程度十分な性能を発揮します。そして、それらは完全に永久無料です。必要なのは個人のコンピューターと十分な電源だけです。現在、PapersGPTはZoteroでのローカルLLMのシームレスな実行をサポートしており、WindowsでもMacでも簡単に実行できます。
Zoteroでワンクリックで無料LLMを実行
環境の初期化
PapersGPT(少なくともv0.2.0)を初めてインストールして起動すると、システムはローカルLLMの実行に必要な依存ライブラリとインストールパッケージを自動的に初期化するのに時間がかかります。GitHubとHuggingFaceに接続できる良好なネットワークを確保してください。このプロセスはバックグラウンドで自動的に実行され、ユーザーは面倒な手動の環境設定やインストールを心配する必要はありません。Windowsの一部のシステム環境では、ファイアウォールがリスクがあると警告する場合があります。インストールプロセスがスムーズに進むように、関連する権限を許可してください。
好きなモデルを選択
LLM実行環境が初期化されると、PapersGPTにローカルLLMオプションが表示され、ローカルマシン環境に応じて設定され、一致するサイズの組み込みオープンソースLLMが提供されます。サポートされているローカル無料モデルを次の表に示します。
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
PCまたはラップトップのGPUメモリの制限により、すべてのモデルが表示されるわけではありません。GPUメモリよりも小さいモデルのみが表示されます。LLMが選択可能として表示されると、ローカルマシンのGPUで安全に実行でき、ローカルの最大のGPUカードで優先的に実行されます。
モデルのダウンロード
gemma 3 4bなどの特定のモデルを選択すると、モデルはHuggingFaceからローカルコンピューターに自動的にダウンロードされます。LLMは一般的に大きいため、ダウンロードには通常ある程度の時間がかかります。ダウンロードの進行状況はPapersGPT上の表示に基づきます。モデルがダウンロードされると、バックグラウンドで自動的にローカルLLM推論サービスが読み込まれ、開始されます。
ローカルLLMとチャット
論文を読みながらローカルLLMとチャットできます。1つの論文を読むことも、複数の論文をまとめて読むこともできます。たとえば、Zotero内の複数の関連論文に基づいて文献レビューを生成できます。非常に便利で使いやすいです。
重要な注意事項
PapersGPTエージェントはWindows上で誤ってトロイの木馬またはウイルスと判断される可能性があります。PapersGPTの関連エージェントは、Microsoft Defenderやその他のウイルス対策ソフトウェアによって誤ってトロイの木馬やウイルスと判断される可能性があります。この場合、次のような異常現象が見られることがあります:
PapersGPTの左側にある「ローカルLLM」項目が表示されない。ローカルモデルをコンピューターにダウンロードできない。ローカルモデルがチャットサービスを提供できない。
したがって、WindowsでローカルLLMを使用したい場合は、Microsoft Defenderやウイルス対策ソフトウェアで安全なPapersGPTエージェントがデバイス上で実行されることを許可してください。
省電力モードでローカルLLMとチャットしないでください
ローカルLLMでPDFとチャットするときは、コンピューターが低電力モード、省電力モードなどで動作していないことを確認してください。これは、ローカルLLMでのPDFチャットにはGPUによる大量の計算が必要であり、省電力モードなどが計算パフォーマンスに影響を与え、PapersGPTの応答を遅くするためです。
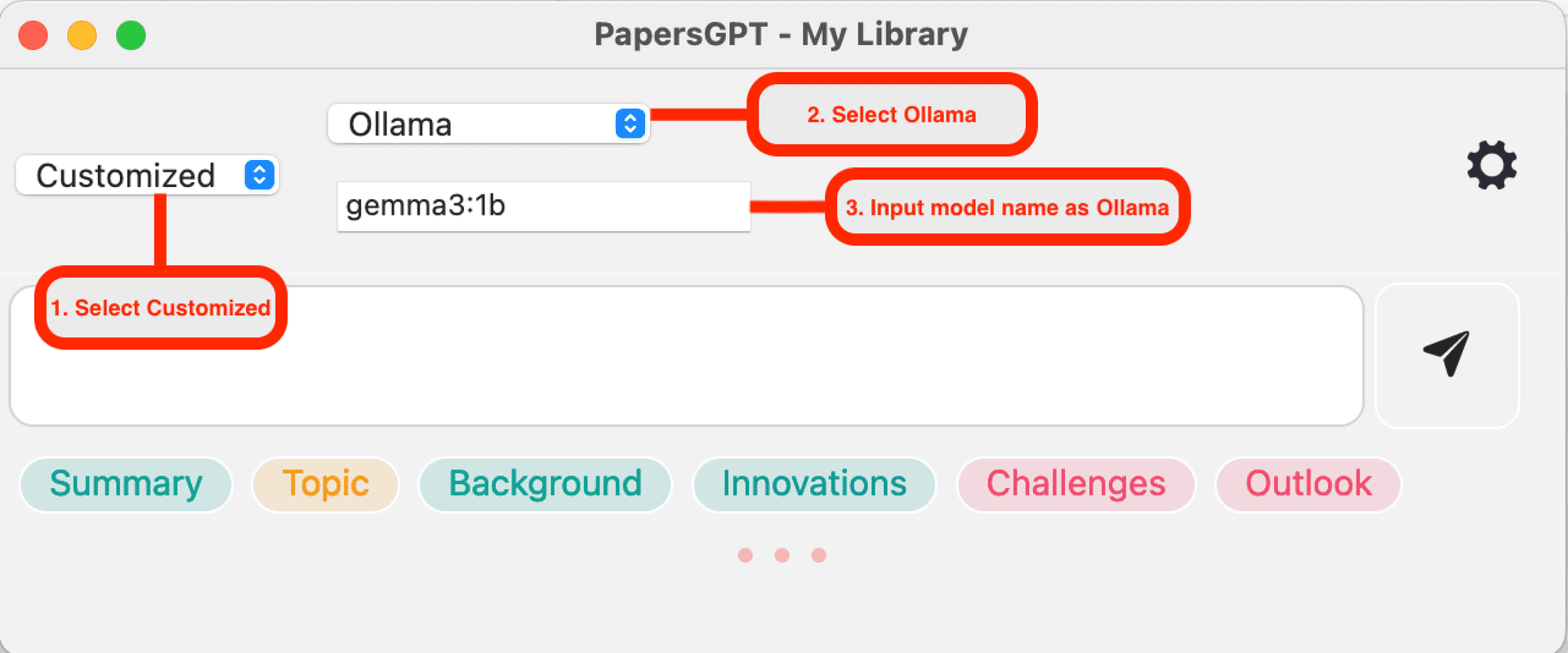
Ollama互換
Ollamaアプリを使用してローカルLLMサービスを起動することに慣れている場合は、PapersGPTでOllamaと同じモデル名('gemma3:1b'など)を入力するだけです