Zotero에서 로컬 무료 LLM과 채팅하기
소개
현재 오픈소스 대규모 언어 모델(LLM)이 빠르게 발전하고 있습니다. 유료 상용 LLM만큼 좋지는 않지만, 일부 오픈소스 LLM은 자동 요약, 논문 리뷰 작성 및 기타 논문 읽기 보조 시나리오에서 어느 정도 충분합니다. 그리고 완전히 영구적으로 무료입니다. 필요한 것은 개인용 컴퓨터와 충분한 전원 공급뿐입니다. 이제 PapersGPT는 Zotero에서 로컬 LLM을 원활하게 실행할 수 있도록 지원하며, Windows나 Mac 플랫폼 모두에서 쉽게 실행할 수 있습니다.
Zotero에서 클릭 한 번으로 무료 LLM 실행
환경 초기화
PapersGPT(최소 v0.2.0)를 처음 설치하고 시작하면, 시스템이 로컬 LLM 실행에 필요한 종속 라이브러리와 설치 패키지를 자동으로 초기화하는 데 시간이 걸립니다. GitHub 및 HuggingFace에 연결할 수 있는 양호한 네트워크를 확인하세요. 이 프로세스는 백그라운드에서 자동으로 실행되며, 사용자는 번거로운 수동 환경 구성 및 설치에 대해 걱정할 필요가 없습니다. Windows의 일부 시스템 환경에서는 방화벽이 위험이 있다고 경고할 수 있습니다. 설치 프로세스가 원활하게 진행되도록 관련 권한을 부여하세요.
원하는 모델 선택
LLM 실행 환경이 초기화되면 PapersGPT에 로컬 LLM 옵션이 나타나며, 로컬 머신 환경에 따라 구성되고 일치하는 크기의 내장 오픈소스 LLM이 제공됩니다. 지원되는 로컬 무료 모델은 다음 표에 나와 있습니다.
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
PC 또는 노트북의 GPU 메모리 제한으로 인해 모든 모델이 표시되지는 않습니다. GPU 메모리보다 작은 모델만 표시됩니다. LLM이 선택 가능한 것으로 표시되면 로컬 머신의 GPU에서 안전하게 실행될 수 있으며, 로컬에서 가장 큰 GPU 카드에서 우선적으로 실행됩니다.
모델 다운로드
gemma 3 4b와 같은 특정 모델을 선택하면, 모델이 HuggingFace에서 로컬 컴퓨터로 자동 다운로드됩니다. LLM은 일반적으로 크기 때문에 다운로드에 보통 시간이 걸립니다. 다운로드 진행 상황은 PapersGPT의 표시를 기준으로 합니다. 모델이 다운로드되면 백그라운드에서 자동으로 로컬 LLM 추론 서비스가 로드되고 시작됩니다.
로컬 LLM과 채팅하기
논문을 읽으면서 로컬 LLM과 채팅할 수 있습니다. 단일 논문을 읽거나 여러 논문을 함께 읽을 수 있습니다. 예를 들어, Zotero에서 여러 관련 논문을 기반으로 문헌 검토를 생성할 수 있습니다. 매우 편리하고 사용하기 쉽습니다.
중요 참고사항
PapersGPT 에이전트는 Windows에서 트로이 목마나 바이러스로 잘못 판단될 수 있습니다. PapersGPT의 관련 에이전트는 Microsoft Defender 또는 기타 바이러스 백신 소프트웨어에 의해 트로이 목마나 바이러스로 잘못 판단될 수 있습니다. 이 경우 다음과 같은 비정상적인 현상이 나타날 수 있습니다:
PapersGPT 왼쪽에 "로컬 LLM" 항목이 나타나지 않습니다. 로컬 모델을 컴퓨터에 다운로드할 수 없습니다. 로컬 모델이 채팅 서비스를 제공할 수 없습니다.
따라서 Windows에서 로컬 LLM을 사용하려면 Microsoft Defender 또는 바이러스 백신 소프트웨어에서 안전한 PapersGPT 에이전트가 기기에서 실행되도록 허용하세요.
절전 모드에서 로컬 LLM과 채팅하지 마세요
로컬 LLM으로 PDF와 채팅할 때는 컴퓨터가 저전력 모드, 절전 모드 등으로 작동하지 않는지 확인하세요. 이는 로컬 LLM으로 PDF와 채팅하려면 GPU의 많은 계산이 필요하며, 절전 모드 등은 계산 성능에 영향을 미쳐 PapersGPT의 응답을 느리게 만들기 때문입니다.
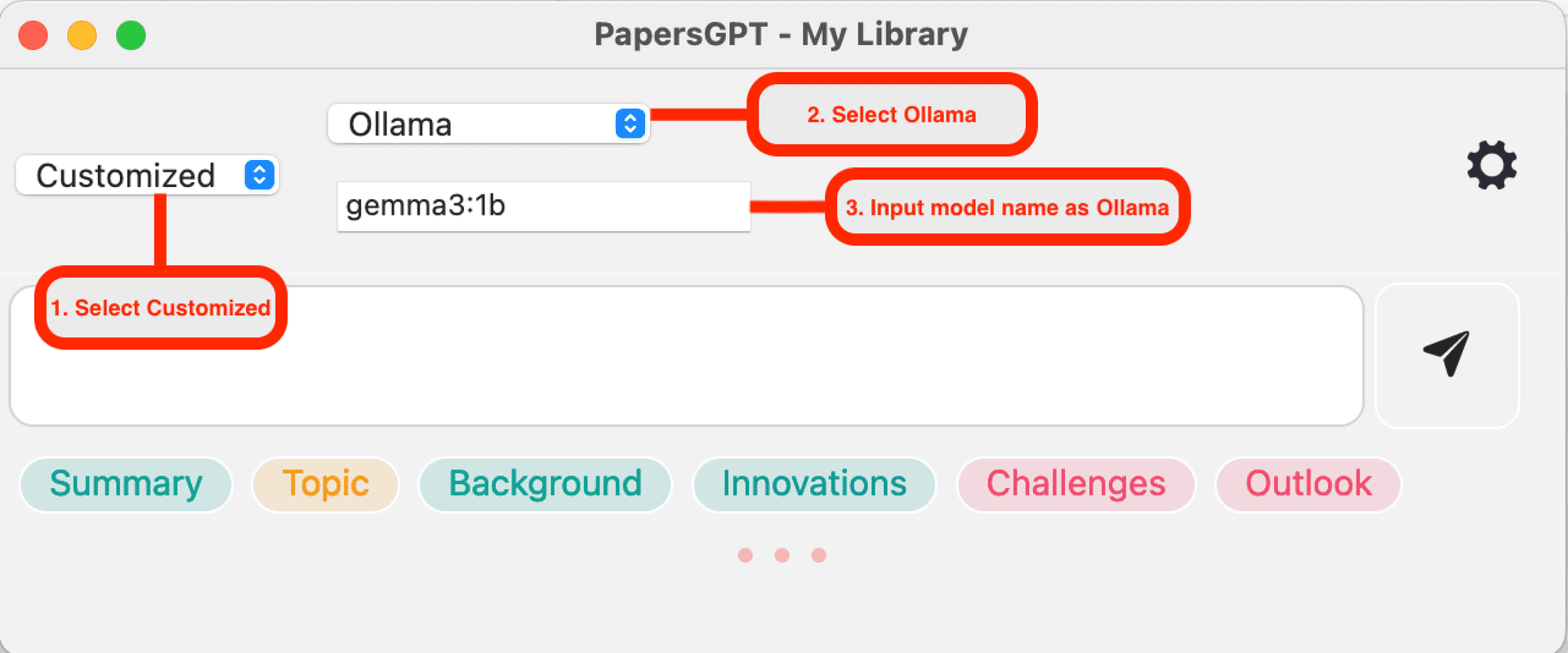
Ollama 호환
Ollama 앱을 사용하여 로컬 LLM 서비스를 시작하는 데 익숙하다면, PapersGPT에 Ollama와 동일한 모델 이름(예: 'gemma3:1b')을 입력하기만 하면 됩니다