Chatta con LLM Locali Gratuiti in Zotero
Introduzione
Oggi, i Modelli Linguistici di Grandi Dimensioni (LLM) open source si stanno evolvendo rapidamente. Sebbene possano non essere eccellenti quanto i LLM commerciali a pagamento, per riassunti automatici, scrittura di recensioni di articoli e altri scenari di lettura assistita, alcuni LLM open source sono sufficienti in una certa misura. E sono sempre completamente gratuiti, richiedendo solo il tuo PC personale e un'alimentazione sufficiente. Ora, PapersGPT supporta l'esecuzione continua di LLM locali in Zotero, sia su piattaforme Windows che Mac, senza sforzo.
Esegui LLM Gratuiti con un Clic in Zotero
Inizializza l'Ambiente
Quando installi e avvii PapersGPT per la prima volta (almeno v0.2.0), il sistema impiegherà del tempo per inizializzare automaticamente le librerie di dipendenza e i pacchetti di installazione necessari per eseguire LLM locali. Assicurati che la rete sia buona e possa connettersi a GitHub e HuggingFace. Questo processo viene eseguito automaticamente in background, senza che gli utenti debbano preoccuparsi di noiose configurazioni manuali dell'ambiente e installazioni. In alcuni ambienti di sistema Windows, il firewall potrebbe avvisare di rischi, concedi i permessi pertinenti per garantire che il processo di installazione proceda senza intoppi.
Scegli il Tuo Modello Preferito
Quando l'inizializzazione dell'ambiente di esecuzione LLM è completa, l'opzione LLM locale apparirà in PapersGPT e sarà configurata in base all'ambiente della macchina locale, con LLM open source integrati di dimensioni corrispondenti. I modelli locali gratuiti supportati sono mostrati nella tabella sottostante.
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
Nota che a causa delle limitazioni della memoria GPU del tuo PC o laptop, non tutti i modelli verranno visualizzati. Solo i modelli la cui dimensione è inferiore alla memoria della tua GPU verranno visualizzati. Una volta che i LLM sono selezionabili, possono essere eseguiti in modo sicuro sulla GPU della tua macchina locale, con priorità di esecuzione sulla tua scheda GPU locale più grande.
Download del Modello
Dopo aver selezionato un modello specifico (es. gemma 3 4b), il modello verrà scaricato automaticamente da HuggingFace sul computer locale. Poiché i LLM sono generalmente grandi, il download richiede solitamente del tempo. L'avanzamento del download verrà visualizzato su PapersGPT. Una volta completato il download del modello, il servizio di inferenza LLM locale verrà caricato e avviato automaticamente in background.
Chatta con il LLM Locale
Chatta con il LLM locale mentre leggi gli articoli. Puoi leggere da un singolo articolo o combinarne più di uno. Ad esempio, puoi generare una revisione della letteratura basata su più articoli correlati in Zotero, il che è molto comodo e facile da usare.
Note Importanti
L'agente PapersGPT potrebbe essere erroneamente segnalato come trojan o virus su Windows. L'agente correlato di PapersGPT potrebbe essere erroneamente segnalato come trojan o virus da Microsoft Defender o altro software antivirus. In questo caso, potresti vedere i seguenti fenomeni anomali:
La voce 'LLM locale' sul lato sinistro di PapersGPT non appare. Il modello locale non può essere scaricato sul tuo computer. Il modello locale non può fornirti il servizio di chat.
Pertanto, se desideri utilizzare LLM locali su Windows, consenti all'agente PapersGPT sicuro di funzionare sul tuo dispositivo in Microsoft Defender o nel software antivirus.
Non chattare con LLM locali in modalità risparmio energetico
Quando chatti con PDF tramite LLM locale, assicurati che il tuo computer non sia in modalità a basso consumo, risparmio energetico o simile. Questo perché chattare con PDF via LLM locale richiede calcoli GPU pesanti e le modalità di risparmio energetico influenzano le prestazioni di calcolo, rendendo le risposte di PapersGPT più lente.
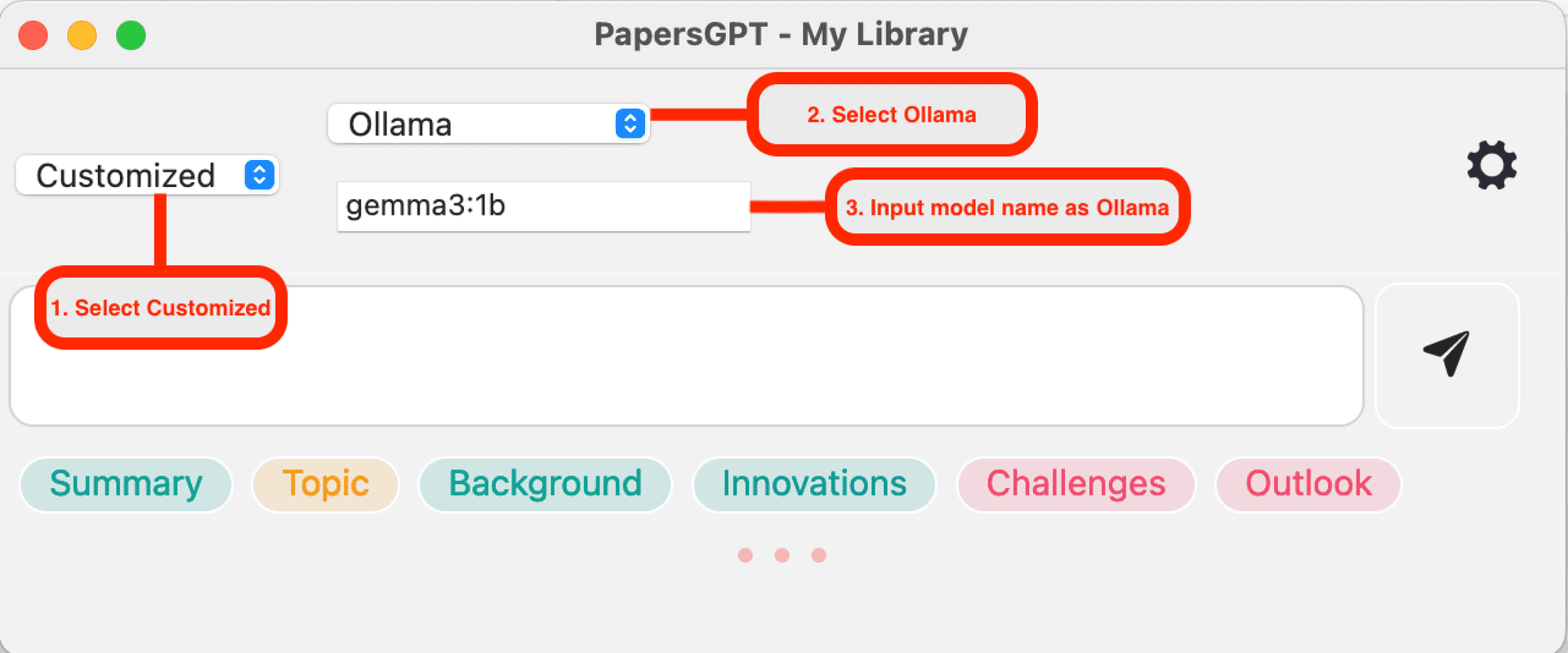
Compatibile con Ollama
Se sei abituato a usare l'app Ollama per avviare il servizio LLM locale, inserisci semplicemente il nome del modello in PapersGPT come in Ollama, ad esempio 'gemma3:1b'