Chatea con LLMs Locales Gratuitos en Zotero
Introducción
Actualmente, los modelos de lenguaje de código abierto (LLMs) se están desarrollando rápidamente. Aunque no son tan buenos como los LLMs comerciales de pago, algunos LLMs de código abierto son suficientes hasta cierto punto en escenarios de resumen automático, redacción de reseñas de artículos y otras ayudas para la lectura de artículos. Y son completamente gratuitos para siempre. Todo lo que necesitas es tu ordenador personal y suficiente suministro eléctrico. Ahora PapersGPT permite ejecutar LLMs locales sin problemas en Zotero, ya sea en Windows o Mac, se puede ejecutar fácilmente.
Ejecuta LLMs gratuitos en Zotero con un solo clic
Inicializar entorno
Cuando instalas e inicias PapersGPT (al menos v0.2.0) por primera vez, el sistema tardará un tiempo en inicializar automáticamente las bibliotecas dependientes y los paquetes de instalación necesarios para ejecutar LLMs locales. Asegúrate de que la red sea buena y pueda conectarse a GitHub y HuggingFace. Este proceso se ejecuta automáticamente en segundo plano, y los usuarios no necesitan preocuparse por ninguna configuración e instalación manual tediosa del entorno. En algunos entornos de sistema en Windows, el firewall puede advertir que hay riesgos. Concede los permisos necesarios para garantizar el progreso fluido del proceso de instalación.
Elige el modelo que más te guste
Cuando el entorno de ejecución de LLMs esté inicializado, la opción de LLM Local aparecerá en PapersGPT, y se configurará según el entorno de la máquina local, con LLMs de código abierto integrados de tamaños coincidentes. Los modelos locales gratuitos compatibles se muestran en la siguiente tabla.
| Provider | Supported Models |
|---|---|
| OpenAI | gpt-oss-20b |
| gemma-3-12b | gemma-3-4b | gemma-3-1b | gemma-3n-e4b | |
| Qwen | qwen-3-8b | qwen-3-4b | qwen-3-1.7b |
| DeepSeek | deepseek-distill-llama | deepseek-distill-llama-small | deepseek-0528-distill-qwen3 | deepseek-0528-distill-qwen3-small | deepseek-distll-qwen-1.5b |
| Microsoft | phi-4 | phi-4-mini-reasoning |
| Mistral | mistral-7b | mistral-7b-small |
| Llama | llama-3.1-8b | llama-3.1-8b-small |
Ten en cuenta que debido a la limitación de la memoria GPU en tu PC o portátil, no se mostrarán todos los modelos. Solo se mostrarán los modelos cuyo tamaño sea menor que la memoria GPU disponible. Una vez que los LLMs se muestren para elegir, se pueden ejecutar de forma segura en la GPU de tu máquina local y se priorizará su ejecución en la tarjeta GPU más grande disponible.
Descarga de modelos
Después de seleccionar un modelo específico, como gemma 3 4b, el modelo se descargará automáticamente desde HuggingFace al ordenador local. Dado que los LLMs son generalmente grandes, suelen tardar algún tiempo en descargarse. El progreso de la descarga se muestra en PapersGPT. Una vez descargado el modelo, el sistema cargará e iniciará automáticamente el servicio de inferencia del LLM local en segundo plano.
Chatea con LLMs locales
Chatea con LLMs locales mientras lees artículos. Puedes leer un solo artículo o varios artículos juntos. Por ejemplo, puedes generar una revisión de literatura basada en múltiples artículos relacionados en Zotero. Es muy conveniente y fácil de usar.
Notas Importantes
El agente de PapersGPT puede ser identificado erróneamente como un troyano o virus en Windows. Los agentes relacionados de PapersGPT pueden ser identificados erróneamente como un troyano o virus por Microsoft Defender u otro software antivirus. En este caso, puedes observar algunos fenómenos anormales:
El elemento "LLM Local" en el lado izquierdo de PapersGPT no aparece. Los modelos locales no se pueden descargar a tu ordenador. Los modelos locales no pueden proporcionar servicio de chat.
Por lo tanto, si deseas usar los LLMs Locales en tu Windows, permite que los agentes seguros de PapersGPT se ejecuten en tu dispositivo en Microsoft Defender o el software antivirus.
No chatees con LLMs locales en modo de ahorro de energía
Al chatear con PDFs usando LLMs locales, asegúrate de que tu ordenador no esté funcionando en modo de bajo consumo, modo de ahorro de energía o modos similares. Esto se debe a que chatear con PDFs usando LLMs locales requiere mucho cálculo de la GPU, y los modos como el ahorro de energía afectarán el rendimiento del cálculo y harán que PapersGPT responda lentamente.
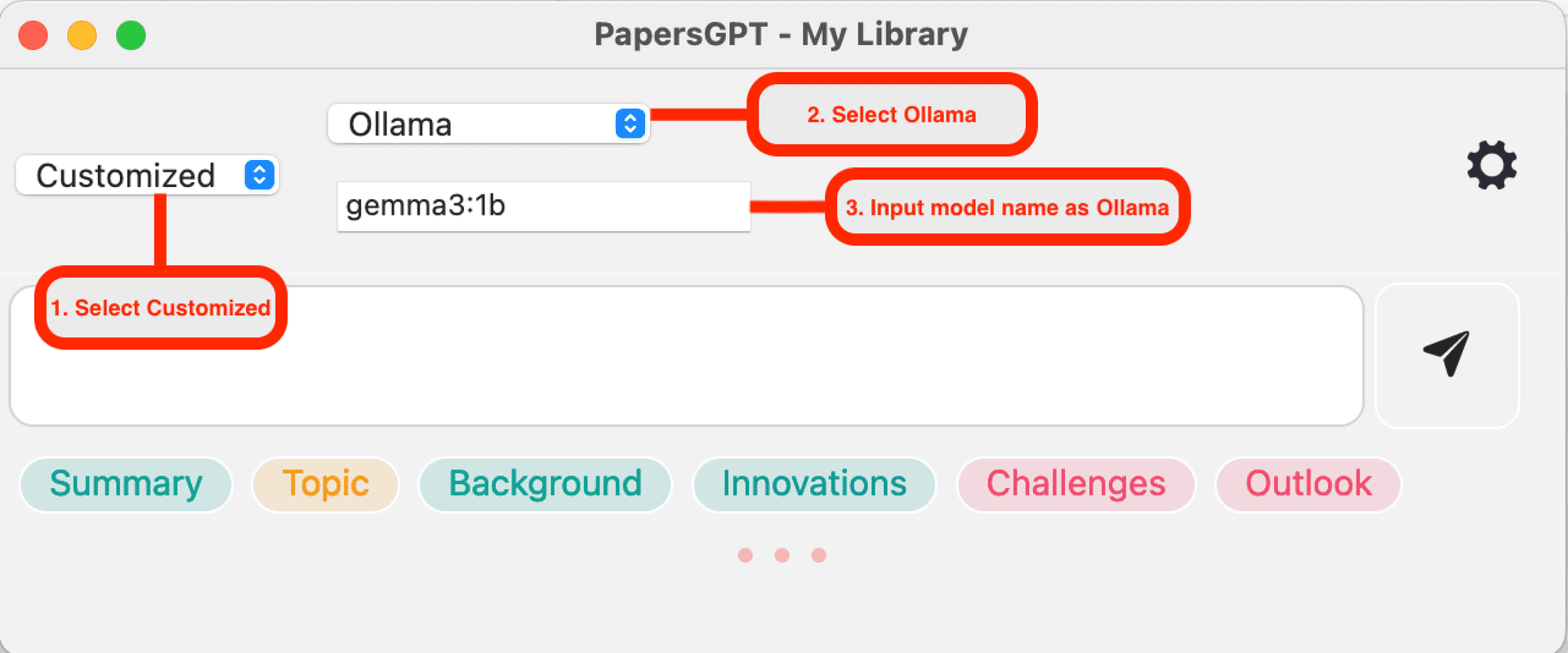
Compatible con Ollama
Si estás acostumbrado a usar la aplicación Ollama para iniciar el servicio LLM local, simplemente ingresa el nombre del modelo igual que en Ollama en PapersGPT, como 'gemma3:1b'